
Linux kernel namespaces
Namespaces are a Linux kernel feature that provides process isolation; they are a fundamental aspect of containers.
There are different types of namespaces, each responsible for its own isolation piece:
- MNT namespace isolates filesystem mounts.
- PID namespace isolates the process tree.
- NET namespace isolates the network stack.
- UTS namespace isolates the hostname.
- USER namespace isolates users and groups.
- IPC namespace isolates interprocess communication (shared segments, semaphores).
- CGROUP namespace limits resources such as RAM and CPU.
When a Linux system starts, it creates one namespace of each type to be shared by all processes.
From a developer’s viewpoint, namespaces are attributes assigned to processes. There is no explicit system call or API to create them. To create a new namespace, we need to create a process and specify which namespaces we want it to have. Additionally, we can change the namespaces of a running process.
- clone syscall is used to create a new process, unlike familiar fork this system call allow child process to be placed into separate namespaces.
- unshare call is used to contoll execution context, including namespaces, without creating a new process. Unless otherwise specified, all processes are placed into ‘common’ namespaces created at system start. It is said that processes share an execution context. Thus, the name unshare is used to change that behavior. Technically, the
unsharecall creates new namespaces.
Amongs other parameters, both calls expect set of flags to indicate which namespaces to place the process into:
CLONE_NEWNSto create new MNT namespace.CLONE_NEWUTSto create new UTS namespace.CLONE_NEWIPCto create new IPC namespace.CLONE_NEWPIDto create new PID namespace.CLONE_NEWNETto create new NET namespace.CLONE_NEWUSERto create new USER namespace.CLONE_NEWCGROUPto create a new cgroup namespace.
cbt run
You might wonder why we are looking into namespaces since we are building the Build Tool, not the Run Tool. The answer is the run command. In a Dockerfile, we have the RUN instruction, and in Buildah, we have the run command.
We must be able to run a specified command in an isolated environment(container) using the container’s root filesystem as a root filesystem.
unshare command
To create a new namespaced process we will use unshare CLI; don’t confuse with unshare syscall.
To illustrate how the unshare command works I’ll post it’s simplified source code:
/* unshare.c
https://man7.org/linux/man-pages/man2/unshare.2.html
A simple implementation of the unshare(1) command: unshare
namespaces and execute a command.
*/
#define _GNU_SOURCE
#include <err.h>
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
static void
usage(char *pname)
{
fprintf(stderr, "Usage: %s [options] program [arg...]\n", pname);
fprintf(stderr, "Options can be:\n");
fprintf(stderr, " -C unshare cgroup namespace\n");
fprintf(stderr, " -i unshare IPC namespace\n");
fprintf(stderr, " -m unshare mount namespace\n");
fprintf(stderr, " -n unshare network namespace\n");
fprintf(stderr, " -p unshare PID namespace\n");
fprintf(stderr, " -t unshare time namespace\n");
fprintf(stderr, " -u unshare UTS namespace\n");
fprintf(stderr, " -U unshare user namespace\n");
exit(EXIT_FAILURE);
}
int
main(int argc, char *argv[])
{
int flags, opt;
flags = 0;
while ((opt = getopt(argc, argv, "CimnptuU")) != -1) {
switch (opt) {
case 'C': flags |= CLONE_NEWCGROUP; break;
case 'i': flags |= CLONE_NEWIPC; break;
case 'm': flags |= CLONE_NEWNS; break;
case 'n': flags |= CLONE_NEWNET; break;
case 'p': flags |= CLONE_NEWPID; break;
case 't': flags |= CLONE_NEWTIME; break;
case 'u': flags |= CLONE_NEWUTS; break;
case 'U': flags |= CLONE_NEWUSER; break;
default: usage(argv[0]);
}
}
if (optind >= argc)
usage(argv[0]);
if (unshare(flags) == -1)
err(EXIT_FAILURE, "unshare");
execvp(argv[optind], &argv[optind]);
err(EXIT_FAILURE, "execvp");
}
The unshare call will change execution context of the calling process by moving it to a new set of namespaces specified in flags variable. Next, the execvp call will execute the command passed as an argument to unshare. Effectivelly this two calls will allow us to create namespaced processed.
Network namespace
The whole point of namespaces is to provide process isolation. Each namespace type isolates it’s corner of the OS. The NET namespace isolates system resources associated with networking: network devices, IPv4 and IPv6 protocol stacks, IP routing tables, firewall rules.
Let’s see how that works. To create a new /bin/bash process in a new network namespace pass the --net option to unshare:
$ sudo unshare --net /bin/bash
Now you should see a new bash session open in a new network namespace. Let’s poke around and ping google:
$ ping google.com
ping: google.com: Temporary failure in name resolution
Hm, let’s ping google’s public DNS:
$ ping 8.8.8.8
ping: connect: Network is unreachable
That’s because we created a new network namespace. The process is isolated. To list available interfaces type ip link:
$ ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
There is only one loopback interface created inside the namespace, and it’s in the DOWN state. On one hand, this is good as we wanted to isolate the process. On the other hand, we have to do additional work configuring the network stack to get connectivity.
Lets look at docker’s drivers list:
| Driver | Description |
|---|---|
| bridge | The default network driver. |
| host | Remove network isolation between the container and the Docker host. |
| none | Completely isolate a container from the host and other containers. |
| overlay | Overlay networks connect multiple Docker daemons together. |
| ipvlan | IPvlan networks provide full control over both IPv4 and IPv6 addressing. |
| macvlan | Assign a MAC address to a container. |
- If we don’t create a namespace we get similar behaviour as with
hostdocker driver; - it we create a namespace and don’t configure it we get
nonebehaviour; - if we create a namespace and configure the network bridge we get
bridge’s driver behaviour.
Mount namespace
To create a new mount namespace pass the --mount flag to unshare:
$ sudo unshare --mount /bin/bash
In a new bash session let’s explore the filesystem:
ls -lia
total 176748
15990786 drwxr-x--- 16 platon platon 4096 Jan 11 13:29 .
15990785 drwxr-xr-x 3 root root 4096 Jun 22 2023 ..
16025054 -rw------- 1 platon platon 9574 Jan 11 09:06 .viminfo
16007681 drwxrwxr-x 5 platon platon 4096 Oct 6 16:40 .vscode-server
16007686 -rw-rw-r-- 1 platon platon 218 Sep 1 12:38 .wget-hsts
16025013 -rw-rw-r-- 1 platon platon 864 Oct 5 08:03 base64
16007684 -rw-rw-r-- 1 platon platon 273 Jun 24 2023 docker-compose.yml
16025014 -rw-rw-r-- 1 platon platon 129034961 Oct 26 14:45 go1.16.7.linux-amd64.tar.gz
9437211 -rwxrwxr-x 1 platon platon 1937408 Oct 26 14:47 hello-world
16025017 -rw-rw-r-- 1 platon platon 219 Oct 26 14:46 hello-world.go
16025012 -rw-rw-r-- 1 platon platon 49864704 Oct 5 07:54 kubectl
16025056 -rw-rw-r-- 1 platon platon 1184 Jan 11 09:14 ns.go
15990798 drwxrwxr-x 11 platon platon 4096 Oct 6 16:40 p
It seems like it didn’t work. I can still see my files. It didn’t isolate anything. Moreover, if I touch hello.txt, exit the shell (delete the namespace) I can still see hello.txt.
Turns out that’s by design; it suppose to work like that. Before explaining why, let’s talk about Linux mounts.
Mounts
A mount is an association of a storage device to a location in the directory tree. This location is called a mount point. So we mount a device at a mount point.
In UNIX there is a single directory tree, there are no drives like in Windows, so instead of having C:\ mapped to a disk partition, we have a root / mounted to particular filesystem.
To work with mounts there is a mount command. Run it without parameters to get list of mounts on your system.
$ mount
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
/dev/nvme0n1p2 on / type ext4 (rw,relatime)
tmpfs on /run/user/1000 type tmpfs (rw,nosuid,nodev,relatime,size=3223224k,nr_inodes=805806,mode=700,uid=1000,gid=1000,inode64)
...
I omitted the output for brevity. As you can see i have /dev/nvme0n1p2 disk mounted at root /. Everything i have under this root is stored on nvme0n1p2.
Each process can have its own list of mounts. You can see what mounts available to a current process by running cat /proc/self/mounts. If you run it you should see the same output as after running the mount command.
At this point I’d like to remind you the definition of mount namespaces – mount namespaces provide isolation of the list of mounts. That means inside process A we can have / mounted to /dev/nvme0n1p2 and inside process B, / can be mounted to /media/usb.
Please note, it doesn’t say we get a filesystem isolation, or a file isolation, we get lists of mounts isolation. So if both A and B have the same mount lists they will see the same data.
And that is exactly what happened when we created a new mount namespace earlier. We saw list of mounts of the parent process.
- If we create a new mount namespace by using
clonesyscall the list of mounts is copied from the parent process’s mount namespace. - If we create a new mount namespace by using
unsharesyscall the list of mounts is copied from the caller’s previous mount namespace. The “previous mount namespace” refers to the mount namespace that the calling process had before it created the new namespace using unshare.
To explain the above statements let’s recall that at start Linux will create a common namespaces of each type. When we run a process, without specifying a flag to create new namespace, the process will end up in these common namespaces.
- So unnamespaced process is actually a process that belongs to a common namespace and has access to all resources. When we
clonethat process withCLONE_NEWNSflag we get mount list from the parent process’s mount namespace, effectivelly getting list of all mounts. - With
unsharesyscall we change namespaces of existing process. When creating a new mount namespace withunsharethe Linux kernel copies the list of mounts a process had prior to executing the unshare syscall.
Peer groups
But that’s not all. The list of mounts is also kept in sync. The main purpose of this behaviour is to allow automatic propagation of mount/unmount events between namespaces. Each mount is marked with a propagation type.
- MS_SHARED type shares mount and unmount event with it’s peer group. A peer group is set of mounts that propagate events to each other.
- MS_PRIVATE is opposite of MS_SHARED, it does not share any events with anyone.
- MS_SLAVE gets events from it master, but does not propagate any events by itself.
- MS_UNBINDABLE is like MS_PRIVATE, but is unbindable, can’t be source or target for propagation events.
The propagation type settings is set per a mount point.
Why dont use chroot?
A chroot can change the apparant root directory for a running process and it’s children. But, it doesn’t change the mount list in common namespace. It’s also possible to escape chroot and access host’s filesystem, so using it has some security issues.
Despite that it can be a valid option, especially for our use case.
PID namespace
PID namespace isolates the process ID number space. PIDs in a new namespace start at 1. If we have 10 processes in 10 PID namespaces they all will have PID of 1.
To create a new pid namespace pass the --pid option to unshare:
$ sudo unshare --pid /bin/bash
bash: fork: Cannot allocate memory
The error happens because unshare syscall when used with the CLONE_NEWPID flag doesn’t really moves the calling process to a new pid namespace, instead it causes children created by the caller to be placed in a new PID namespace. A process’s PID namespace is determined when that process is created and can’t be changed. To fix that we need to add --fork option to unshare:
$ sudo unshare --pid --fork /bin/bash
Now it works. To get PID of the current process we can run echo $$:
$ echo $$
1
proc
While the PID namespace isolates process IDs, it doesn’t isolate processes themselves, we can still see other processes running:
$ ps
PID TTY TIME CMD
49323 pts/1 00:00:00 sudo
49324 pts/1 00:00:00 unshare
49325 pts/1 00:00:00 bash
49345 pts/1 00:00:00 ps
This happens because ps, htop and other commands of this kind take their info from /proc – a pseudo-filesystem which provides an interface to kernel data structures. Most of the files inside /proc are readonly, but some are writable.
Usually the proc is mounted automatically, but we can also mount it with the following command:
mount -t proc proc /proc
But we can’t simply mount it inside the NET namespace, we also need to create a mount namespace, so that the list of mounts on the host is not changed.
$ sudo unshare --pid --fork --mount /bin/bash
$ ps
PID TTY TIME CMD
49354 pts/1 00:00:00 sudo
49355 pts/1 00:00:00 unshare
49356 pts/1 00:00:00 bash
49363 pts/1 00:00:00 ps
$ mount -t proc proc /proc
$ ps
PID TTY TIME CMD
1 pts/1 00:00:00 bash
10 pts/1 00:00:00 ps
As you can see, after mounting the /proc we have a “process list” isolation as well.
The init process
The first process created in a new PID namespace by using the clone syscall with the CLONE_NEWPID flag,
or
the first child created by a process after unshare syscall with the CLONE_NEWPID flag,
is considered to be the init process for that namespace.
The init process becomes the parent for any orphaned child process. When a process exits most of its resources are released, but it still remains in the process table, because that is where it’s exit code is stored. If a parent retrieves a child’s exit code the child process is removed from the process table. If not, the child process becomes a zombie. A zombie process is eventually assigned a new parent – the init process which retrieves the exit code and removes the record from the process list.
If the init process terminates it’s children are terminated with SIGKILL signal.
Notice how there is no way to specify a namespace’s configuration. We get a new namespace and it’s up to us to configure it once we are in. For the mount and pid namespaces it means to mount containers FS and the /proc. For the NET namespace it means to configure the network stack.
So before running the actual process, we need to run a bootstrapper process to do the proper configuration.
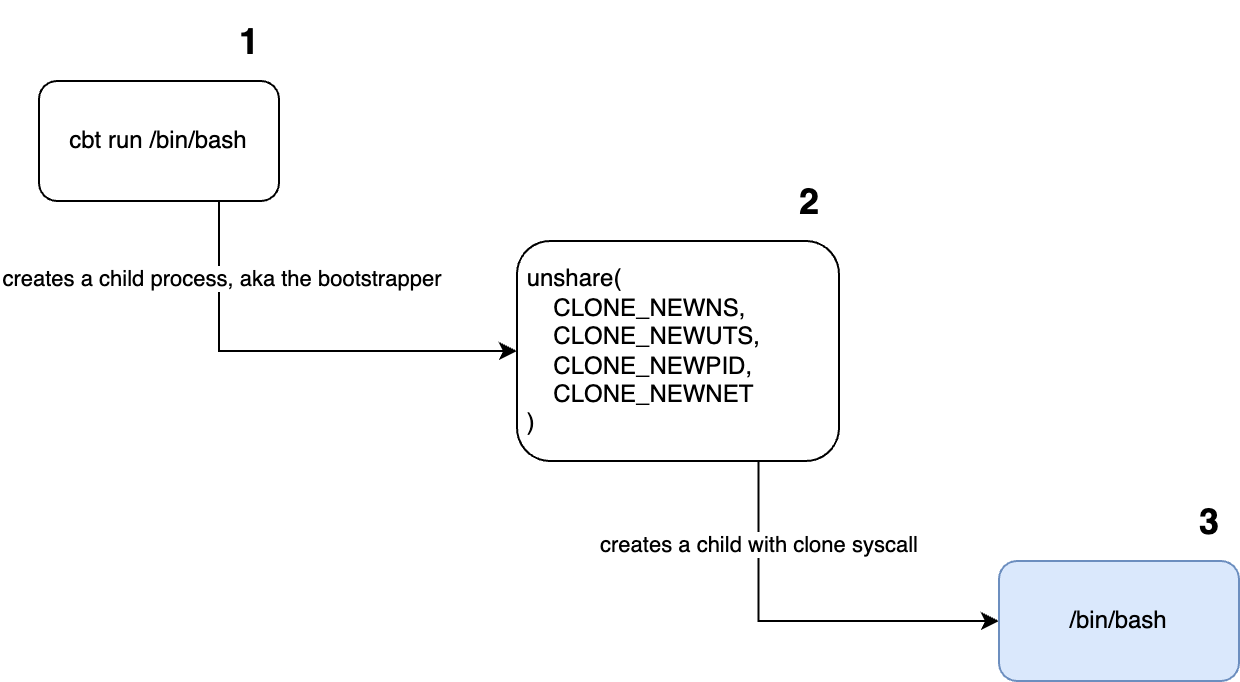
At step 1 user executes cbt run passing a command to execute in a container – /bin/bash.
At step 2, cbt run creates a child process. This process uses unshare syscall to enter the new namespaces and performs their configuration.
At step 3, the child process creates it’s child – the /bin/bash process.
What would happen if the 1st child dies for some reason? The 2nd child could still be running, but we have no way of knowing it. This is where the whole concept of init processes comes into play.
We can appoint a process to be a reaper. A reaper fulfills the role of init process for its descendant processes. If the 1st child dies the 2nd will be reparented to cbt run’s process, instead of systems init process. So we can collect it’s exit code.
UTS namespace
The UTS namespace is simple, it isolates two system identifiers: the hostname and the NIS domain name. To create a new UTS namespace pass the --uts option to unshare:
$ sudo unshare --uts /bin/bash
$ hostname # current hostname
minisforum
$ hostname inside-ns # change the hostname inside UTS namespace
$ hostname # verify hostname
inside-ns
$ exit # get back to original shell
$ hostname # verify hostname is not changed
minisforum
User namespace
The user namespace isolates security identifiers: user IDs, group IDs, and capabilities.
- A process may have different user IDs or group IDs inside and outside a user namespace.
- The first process in a new USER namespace gets the full list of capabilities.
Let’s get visual for a second. Imagine we have a process, X, created without any flags to create new namespaces, so it is a member of all common namespaces.
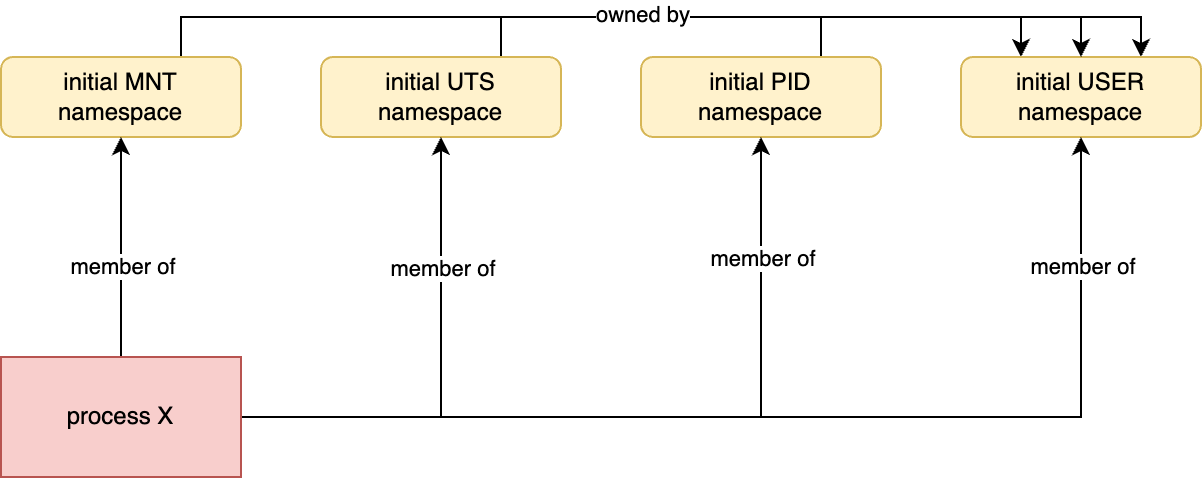
One thing I didn’t mention before is that all namespaces, except for the user namespace, have an owning user namespace. I’ve highlighted only four common namespaces in yellow just to save space.
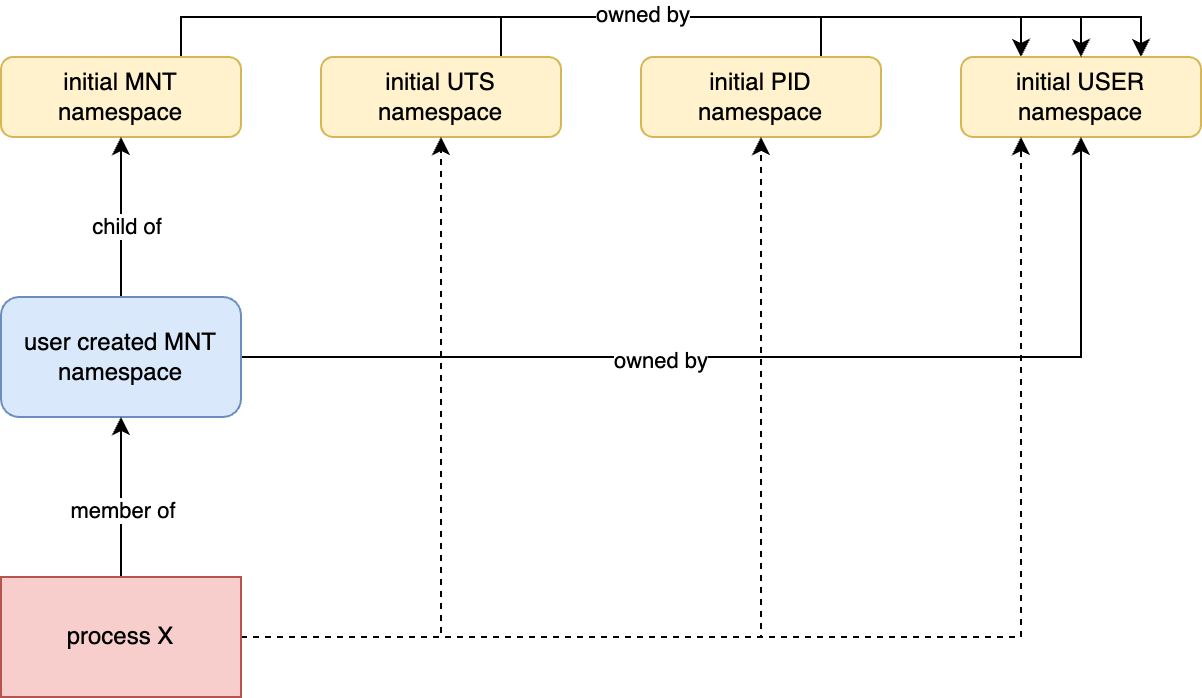
Another thing I didn’t mention is that namespaces are nested; they can have parents and children. When we create a new namespace, it becomes a child of the current namespace of the same type we are in. In the picture below, we have a new MNT namespace whose parent is the common MNT namespace. This new MNT namespace also owned by the common USER namespace.
Now let’s complicate things by adding a new USER namespace. The blue MNT namespace is now owned by the blue USER namespace, it’s no longer owned by the common USER namespace.
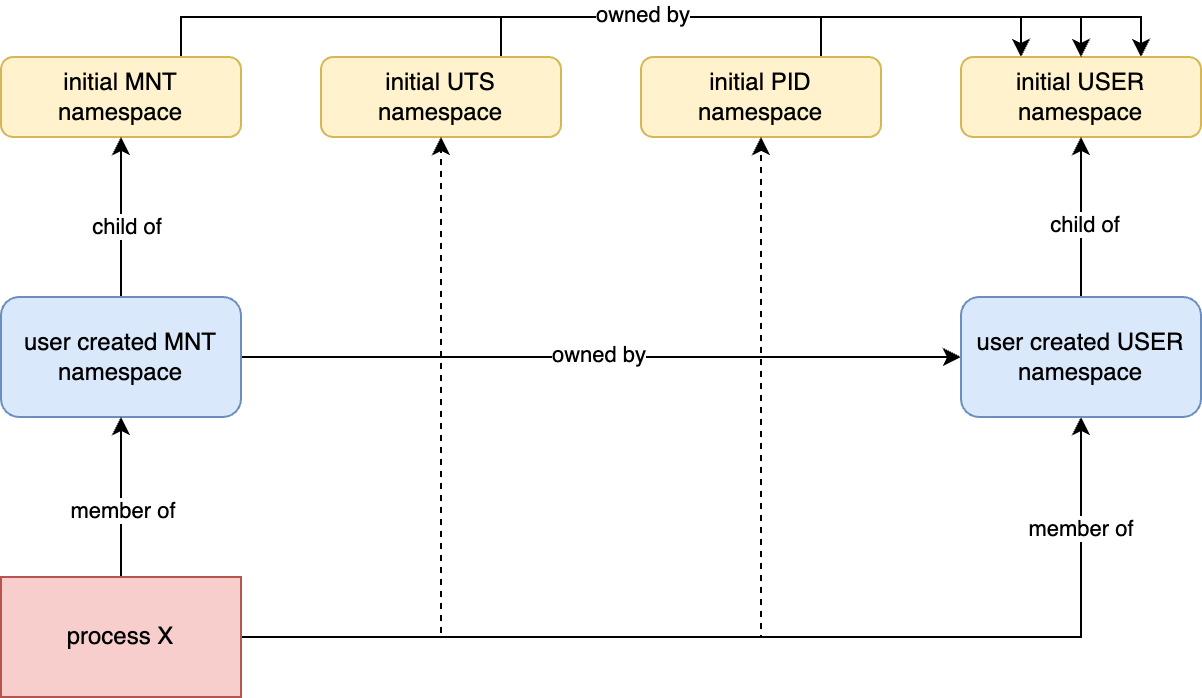
The reason this is important is that an owning user namespace is used to verify a process’s capabilities.
Before, we used sudo to run the unshare program. That’s because all namespaces, except for the user namespace, require the CAP_SYS_ADMIN capability. A user namespace can be created by a regular, unprivileged user.
To create a new user namespace pass the --user option to unshare. But this time, let’s do this without sudo as unprivileged user.
$ id
uid=1001(bob) gid=1001(bob) groups=1001(bob)
$ unshare --user /bin/bash
$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)
And now, we are nobody. This happened because we didn’t specify user mapping. The kernel doesn’t know which user to use inside the newly created user namespace. To fix this we can ask unshare program to create that mapping for us by using the --map-root-user flag:
$ id
uid=1001(bob) gid=1001(bob) groups=1001(bob)
$ unshare --user --map-root-user /bin/bash
$ id
uid=0(root) gid=0(root) groups=0(root)
While inside this namespace try to change the hostname:
$ hostname example
hostname: you must be root to change the host name
The reason it says we must be root, even though we are root, is because of this phrase: an owning user namespace is used to verify a process’s capabilities.
After running unshare --user --map-root-user /bin/bash we get the following situation:
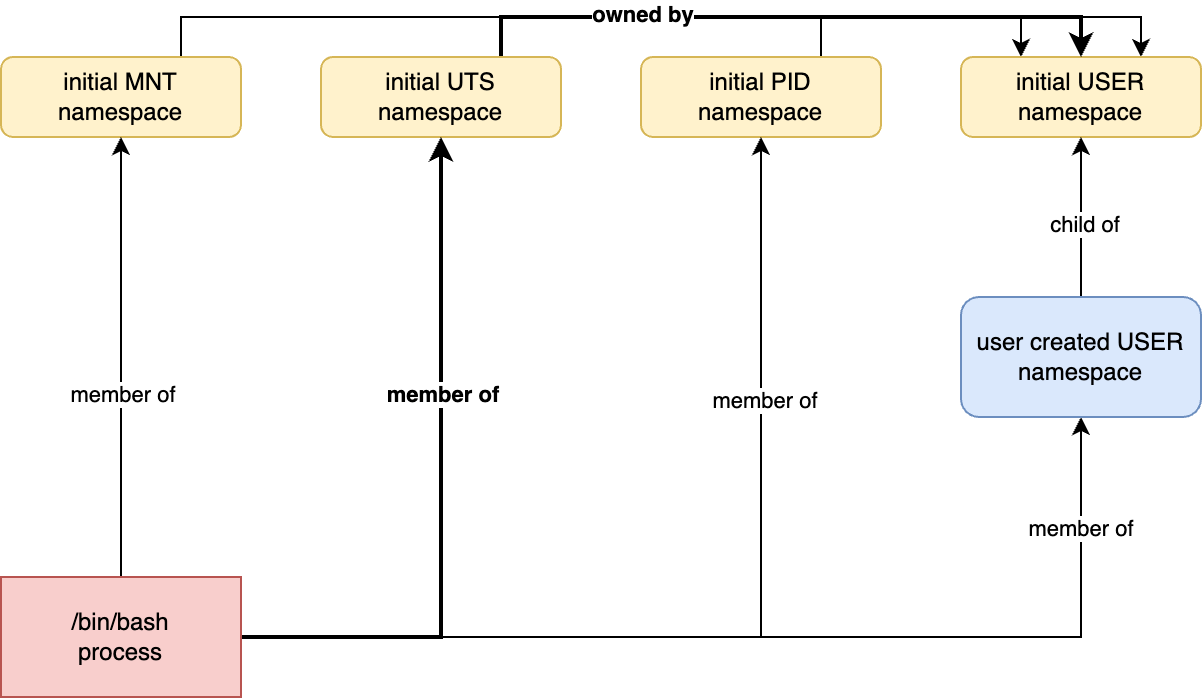
Each resource in Linux is governed by a namespace. The hostname is governed by the UTS namespace. The red process is a member of the common UTS namespace, which is owned by the common user namespace. Do we have any permissions in the common user namespace? NO. Because outside of the blue user namespace we are unprivileged user 1001(bob). To fix the situation let’s run this code:
unshare --user --map-root-user --uts /bin/bash
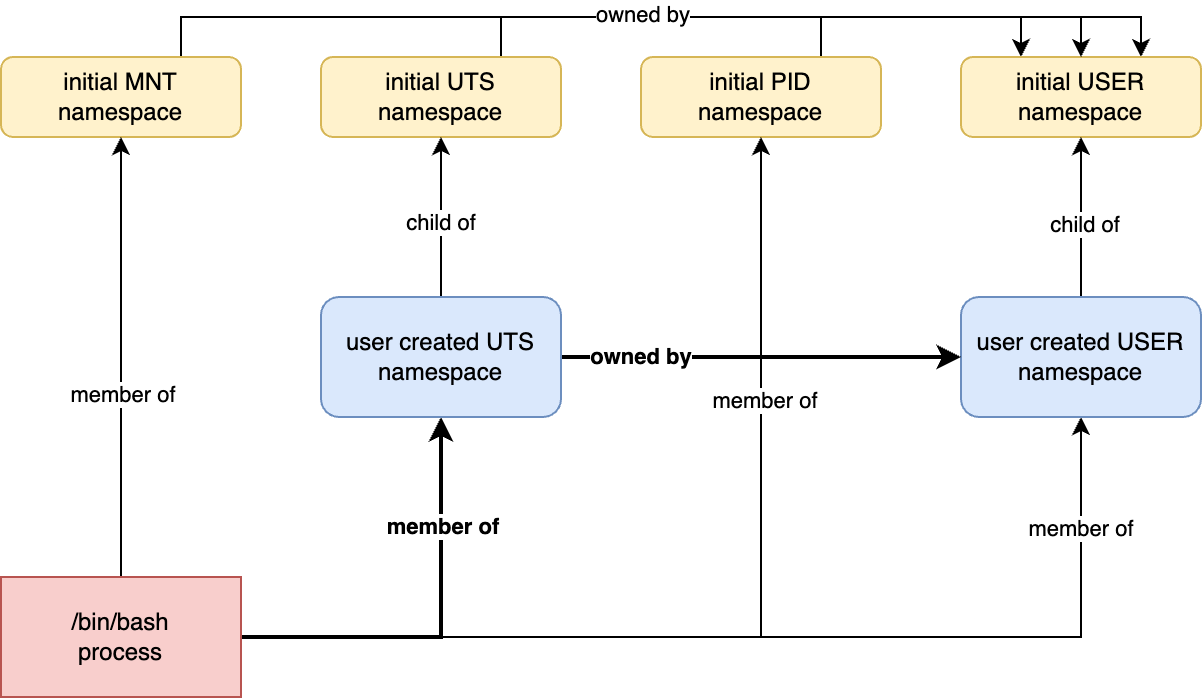
Now the situation is different. The red process is a member of the blue user-created UTS namespace which is owned by the blue user-created user namespace. And within the user-created user namespace the process has all the capabilities. Hostname change is allowed.
I hope this all makes sense. There is a good video on YouTube that does an excellent job of explaining this behavior.
Closing notes
What must exist for the command below to succeed?
dnf -y httpd
First, we must have the dnf command installed and available in the PATH. Second, we need to ensure the existence of the directory tree expected by this command.
All of the above if provided by the container image. In order to get that directory tree along with all the files we need to:
- Create a new mount namespace.
- Mark all mounts as
MS_PRIVATE, so that they don’t propagate events. - Unmount root
/. - Mount a new filesystem at
/.
This is essentially what container runtimes do. Container images provide a new filesystem in form of layers. Each layer is a filesystem diff. Diffs are merged together to get a unified view by using a filesystem such as OverlayFS. This unified view is then mounted at / inside a mount namespace.
What about networking? Obviously, since we run the dnf we want that network connectivity. However, at the same time we have no need for container-to-container connectivity, thus no need to create a network bridge, or the NET namespace itself.
It is ideological to have only one process in a container, and since there is only one process, it’s logical for it to have an ID of 1, because a container is an isolated environment. Therefore, we need a PID namespace and /proc mounted inside a new MNT namespace for the same reason.
In order to create NET, PID, or MNT namespaces we need root privileges, which means we will be root inside those namespaces. Even if we create MNT, NET, UTS, IPC, PID, etc. namespaces to isolate all the system resources, we are still running as the root user. If some process escapes the isolation boundary, the host system will become completely compromised.
The only namespace that doesn’t require root privileges is the user namespace. But there is a caveat – an owning user namespace is used to verify a process’s capabilities. So we must also create NET, PID, MNT or any other namespaces to be able to change the governed resources.
And this is where “Rootfull vs Rootless containers” discussion begins. If we want to have docker-like volumes we have to mount them on the host. But a normal user cannot mount a filesystem, we need root. If we go another way around and create a user namespace and a mount namespace, the list of mounts will be isolated and not visible to the host.
For the sake of cbt run I decided to go with Rootfull and require root privileges.
References
- https://tbhaxor.com/pivot-root-vs-chroot-for-containers/
- https://tbhaxor.com/how-do-docker-run-containers-under-the-hood
- https://medium.com/@william.la.martin/dont-fear-the-subreaper-19c8127c031e
- https://www.schutzwerk.com/en/blog/linux-container-namespaces02-mnt/
- https://man7.org/linux/man-pages/man2/mount.2.html
- https://opensource.com/article/19/3/tips-tricks-rootless-buildah
- https://www.redhat.com/sysadmin/buildah-unshare-command
- https://man7.org/linux/man-pages/man7/namespaces.7.html
- https://medium.com/inside-sumup/containers-from-scratch-part-1-b719effd1e0a
- https://docs.kernel.org/userspace-api/unshare.html
- https://blog.quarkslab.com/digging-into-linux-namespaces-part-1.html#:~:text=Namespaces%20can%20also%20be%20created(unshares%20the%20current%20ones).
- https://medium.com/@ssttehrani/containers-from-scratch-with-golang-5276576f9909
- https://tbhaxor.com/docker-resource-management-in-detail/
- https://itnext.io/container-runtime-in-rust-part-i-7bd9a434c50a
- https://lwn.net/Articles/689856/#:~:text=A%20peer%20group%20is%20a,source%20for%20a%20bind%20mount.
- https://man7.org/linux/man-pages/man2/unshare.2.html
- https://stackoverflow.com/questions/68704803/unshare-command-doesnt-create-new-pid-namespace
- https://blog.quarkslab.com/digging-into-runtimes-runc.html
- https://book.hacktricks.xyz/linux-hardening/privilege-escalation/linux-capabilities
- https://man7.org/linux/man-pages/man5/proc.5.html
This post is part of a series.
- Part 1: Container build tool
- Part 2: How-to build OCI Image by hands
- Part 3: Building OCI images with Go. No run command yet
- Part 4: How to Tar/Untar container layers in Go
- Part 5: Linux kernel namespaces
- Part 6: Mini container runtime in Go
- Part 7: Union mount